
The author of this article, Ashis Chowdhury, is a Technical Architect working in London and has well over two decades of practical experience designing and building enterprise data-warehousing, ETL, and business-intelligence solutions across organizations worldwide. With experience in the highest technical and leadership roles in organizations such as Cognizant, Deloitte, Barclays Capital, and Bupa, and working as an independent client advisor, Ashis possesses significant architectural expertise combined with a proven track record of full-lifecycle solution delivery, team building, and stakeholder management. Ashis holds a Master of Engineering degree in Manufacturing Engineering from the Indian Institute of Science and continues to guide data-driven transformations for worldwide organizations.
ProjectManagers.net presents this article to our readers and the digital community in full with the author’s stated permission.
The fake news problem is everywhere in today’s digital society; in fact, we could say that it seems to be getting even worse. Misinformation spreads so rapidly through social media and other online platforms that it has become a part of the way we communicate virally. Tools to identify and combat this kind of rippling news are needed urgently.
“Fake news” isn’t exactly a new term in itself, particularly in the age of digital media. Information–and misinformation–flows faster than ever before, from social media platforms to news websites millions of people turn to for accurate information, and the other way around. This misinformation affects financial markets, influences elections, and even leads to public health crises.
Given these high stakes, it has been up to the tech professionals of the world to identify scalable and reliable ways to spot–and combat–misinformation online. This is where Natural Language Processing (NLP), comes into play. NLP tools offer methodologies that can search through massive volumes of data and spot misinformation before it reaches its audience. Let’s see exactly how.
How NLP Helps in Fake News Classification
Natural Language Processing sits at an intersection of linguistics and computer science. It helps us understand and interpret human languages at a previously unimaginable scale, and it has been instrumental in developing models that are capable of processing text for various cues and patterns that often accompany fake news. Those can be sensationalist language or inconsistencies in tone, for example.
One of the most accessible and versatile programming languages, Python, has become the de facto standard in the community that works on machine learning. Its many libraries, such as NLTK, SpaCy, and Hugging Face’s Transformers, make the task of parsing text for fake news detection or sentiment analysis simple. At this point, we should look closely at how easy it is to carry out those tasks in Python.
Building a Fake News Classification Model in Python
We will go over the steps involved in constructing a false news classifier in Python. We will work with a dataset comprising labeled news articles and use various natural language processing (NLP) methods to prepare the text for machine learning. We will perform feature extraction, and then we will train a model using those features.
Prerequisites
- Basic understanding of Python programming
- Python is installed on your system
- Familiarity with machine learning concepts
Step 1: Set Up the Environment
Let’s get started by setting up our environment. Ensure you have Python and the necessary libraries installed.
1. Install Python 3.x (Recommended: v3.9 or later).
2. Create a new project directory and navigate into it. Open a new terminal and navigate to the folder where you want to have the project, and run the following command:
> mkdir fake_new_classification_project
> cd fake_new_classification_project
3. Create and activate a virtual environment:
> python3 -m venv .venv
source .venv/bin/activate # For macOS/Linux
# OR
.venv\Scripts\activate # For Windows
4. Install the required libraries using pip:
– Libraries: `pandas`, `numpy`, `scikit-learn`, `nltk`, `matplotlib`, `seaborn`
> pip install pandas numpy scikit-learn nltk matplotlib seaborn
Step 2: Import Libraries
Next, we’ll import the libraries that form the backbone of our classifier. This includes tools for data manipulation, machine learning, and NLP:
“`python
import pandas as pd
import numpy as np
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
import matplotlib.pyplot as plt
import seaborn as sns
# Download NLTK data
nltk.download(‘punkt_tab’)
nltk.download(‘stopwords’)
“`
Step 3: Load the Dataset
For this tutorial, we will use a dataset containing news articles labeled as “real” or “fake”. You can use any dataset available online, such as the Fake News Detection dataset from Kaggle.
“`python
# Load the dataset
real_news = pd.read_csv(‘True.csv’)
fake_news = pd.read_csv(‘Fake.csv’)
# Add labels
real_news[‘label’] = 1 # 1 for real news
fake_news[‘label’] = 0 # 0 for fake news
# Combine the datasets
news_df = pd.concat([real_news, fake_news], ignore_index=True)
# Shuffle the dataset
news_df = news_df.sample(frac=1).reset_index(drop=True)
# Display the first few rows
print(news_df.head())
“`
Step 4: Preprocess the Data
Text preprocessing is a crucial step in NLP. We need to preprocess the text data to enhance our classifier’s performance. We will perform the following steps:
- Lowercasing: Convert all text to lowercase.
- Tokenization: Split the text into individual words.
- Stopword Removal: Remove common words that do not contribute much to the meaning.
- Stemming/Lemmatization: Reduce words to their base or root form.
“`python
def preprocess_text(text):
# Lowercase the text
text = text.lower()
# Tokenize the text
tokens = word_tokenize(text)
# Remove stopwords
stop_words = set(stopwords.words(‘english’))
tokens = [word for word in tokens if word not in stop_words]
# Join tokens back into a string
preprocessed_text = ‘ ‘.join(tokens)
return preprocessed_text
# Apply preprocessing to the text column
news_df[‘text’] = news_df[‘text’].apply(preprocess_text)
# Display the first few rows after preprocessing
print(news_df.head())
“`
Step 5: Feature Extraction
To enable our machine learning model to process the text data, we will use the TF-IDF (Term Frequency-Inverse Document Frequency) vectorizer to convert the text into numerical features. TF-IDF reflects the importance of a word in a document relative to the entire corpus:
“`python
# Initialize the TF-IDF Vectorizer
tfidf_vectorizer = TfidfVectorizer(max_features=5000)
# Fit and transform the text data
X = tfidf_vectorizer.fit_transform(news_df[‘text’]).toarray()
# Get the labels
y = news_df[‘label’]
“`
Step 6: Split the Data
Now, we’ll split the dataset into training and testing sets. This split ensures that we can train our model on one part of the data and evaluate its performance on another:
“`python
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
“`
Step 7: Train a Machine Learning Model
We will use the Multinomial Naive Bayes classifier, which is commonly used for text classification tasks:
“`python
# Initialize the classifier
classifier = MultinomialNB()
# Train the classifier
classifier.fit(X_train, y_train)
# Predict on the test set
y_pred = classifier.predict(X_test)
“`
Step 8: Evaluate the Model
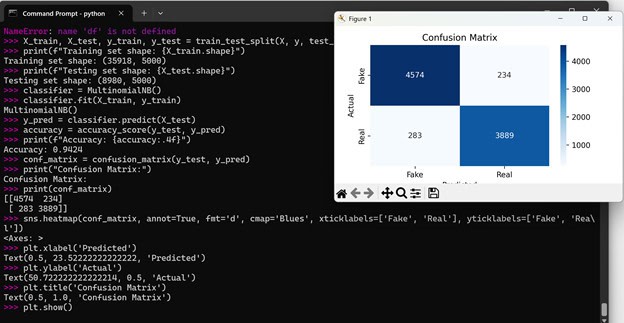
Let’s evaluate the performance of the model using accuracy, confusion matrix, and classification report:
“`python
# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print(f”Accuracy: {accuracy:.4f}”)
# Confusion matrix
conf_matrix = confusion_matrix(y_test, y_pred)
print(“Confusion Matrix:”)
print(conf_matrix)
# Plot confusion matrix
sns.heatmap(conf_matrix, annot=True, fmt=’d’, cmap=’Blues’, xticklabels=[‘Fake’, ‘Real’], yticklabels=[‘Fake’, ‘Real’])
plt.xlabel(‘Predicted’)
plt.ylabel(‘Actual’)
plt.title(‘Confusion Matrix’)
plt.show()
# Classification report
print(“Classification Report:”)
print(classification_report(y_test, y_pred, target_names=[‘Fake’, ‘Real’]))

“`
Step 9: Improve the Model (Optional)
To improve the model, you can try the following:
- Hyperparameter Tuning: Use GridSearchCV or RandomizedSearchCV to find the best hyperparameters for the model.
- Feature Engineering: Experiment with different text preprocessing techniques, such as lemmatization or using n-grams.
- Advanced Models: Try more advanced models like Logistic Regression, Random Forest, or even deep learning models like LSTM.
Step 10: Save the Model
Once you are satisfied with the model, you can save it for future use.
“` python
import joblib
# Save the model
joblib.dump(classifier, ‘fake_news_classifier.pkl’)
# Save the vectorizer
joblib.dump(tfidf_vectorizer, ‘tfidf_vectorizer.pkl’)
“`
Step 11: Load and Use the Model
To use the saved model for predictions, load it and apply it to new data.
“`python
# Load the model
classifier = joblib.load(‘fake_news_classifier.pkl’)
# Load the vectorizer
tfidf_vectorizer = joblib.load(‘tfidf_vectorizer.pkl’)
# Example: Predict on new text
new_text = “This is a sample news article.”
preprocessed_text = preprocess_text(new_text)
vectorized_text = tfidf_vectorizer.transform([preprocessed_text]).toarray()
prediction = classifier.predict(vectorized_text)
print(“Prediction:”, “Real” if prediction[0] == 1 else “Fake”)
“`
Conclusion
In this article, we’ve built a fake news classifier using NLP techniques in Python. This classifier can be further enhanced by fine-tuning parameters, experimenting with different algorithms, or incorporating more advanced NLP techniques. By continuously evaluating and updating the model, you’ll ensure its ongoing effectiveness in identifying fake news.
Suggested articles:
- 7 Project Management Strategies to Speed Up Your Python Development
- How Python Empowers Project Managers with Automation and Data-Driven Insights

ProjectManagers.net is a website that provides articles about project management software, training, templates, and resources tailored for project managers. Enhance skills and streamline workflows.